

Introduction
Materials and Methods
연구 대상 및 생육조사
다중분광 영상 취득
고추 시들음병 감염여부 데이터 수집
다중분광 영상 처리
통계분석
Results and Discussion
Case 1에 대한 분류 모델
Case 2에 대한 분류 모델
Case 3에 대한 분류 모델
고추 시들음병 분류 모델에 대한 고찰
Conclusion
Introduction
고추(Capsicum annuum L.)는 한국 음식에서 빼놓을 수 없는 중요한 양념 채소로, 전체 채소 중에서 가장 많은 재배면적과 수확량을 차지한다(RDA, 2020). 그러나 고추 재배는 흰가루병, 잎마름병, 세균점무늬병, 시들음병 등의 바이러스에 제약을 받는다(Gabrekiristos and Demiyo, 2020). 특히 시들음병(Fusarim wilt)은 전 세계 고추 생산에 지속적인 위협을 주고 있다(Engalycheva et al., 2024). 시들음병 발생 시 초기 대응이 늦어지면 수확량과 품질에 큰 영향을 미칠 수 있기 때문에, 이를 조기에 탐지하고 효과적으로 관리하는 연구가 필수적이다.
최근 농업 분야에서는 무인 항공기(UAV, Unmanned Aerial Vehicle)를 활용한 비파괴적인 작물 연구가 활발히 이루어지고 있다(Kang et al., 2021; Sun et al., 2023). 무인기에는 다양한 센서를 장착하여 사용할 수 있으며 그중 다중분광 센서는 질병으로 인한 식물 영양 상태와 대사 또는 생물학적 변화를 가시광(RGB)영역을 벗어난 특정 스펙트럼 파장을 통해 감지할 수 있다(Peng et al., 2022).
다중분광 센서를 이용하여 포도나무의 곰팡이병을 탐지하는 연구(Kerkech et al., 2020)와 바나나의 시들음병을 탐지하는 연구(Zhang et al., 2022)도 진행되었으며, 소나무의 시들음병을 조기에 탐지하는 연구(Yu et al., 2021)도 진행된 바 있다. 또한, 머신러닝 분류 알고리즘을 이용하여 벼 잎의 병을 탐지하는 연구(Ahmed et al., 2019)와 옥수수 잎의 병을 탐지하는 연구(Panigrahi et al., 2020)도 진행되었다.
작물의 질병탐지에 대한 많은 연구는 실험실 환경에서 수집된 RGB 기반 이미지 데이터셋을 사용하여 진행되어왔고(Ahmed et al., 2019; Jung et al., 2023; Ramesh et al., 2018), 실제 농업 현장에서 데이터를 수집하여 병증이 아직 확인되지 않은 작물의 반사값을 통해 병증을 조기에 탐지하는 연구는 부족하다.
따라서 본 연구는 실제 농가에서 취득한 UAV기반 다중분광 영상으로부터 추출된 반사값을 바탕으로 식생지수를 산출하고, 이를 머신러닝 분류 알고리즘에 적용하여 고추 시들음병의 발생여부를 조기에 탐지하는 모델을 개발하여 고추의 생산성 향상에 기여하는 것을 목표로 한다.
Materials and Methods
연구 대상 및 생육조사
본 연구는 전라북도 김제시 용지면 예촌리 농가포장(35°50′34.07″N 127°57′43.2″E, Fig. 1)에서 재배되고 있는 고추(Capsicum annuum L., Colormura)를 대상으로 진행하였다. 고추는 2023년 5월 2일에 정식하였고, Fig. 1(a)와 같이 1열에 재배되고 있는 30개의 묘목을 대상으로 6월 27일, 7월 27일, 8월 25일에 생육모니터링을 위해 초장, 경경, 마디수, 착과수를 조사하였다.

다중분광 영상 취득
다중분광 영상은 회전익 무인기인 Matrice 300 RTK(DJI Technology Inc, China)에 다중분광 센서(Table 1)인 Altum-PT (MicaSense Inc, USA)를 탑재하여 비행 고도 25 m, 비행 속도 4 m/s, 종횡비 중첩도 75%로 6월 28일, 7월 27일, 8월 26일 정오에 촬영되었다.
Table 1.
Multispectral Sensor.
고추 시들음병 감염여부 데이터 수집
고추의 생육조사를 진행하던 중 7월 27일에 15개 샘플에서 시들음병(Fusarium wilt)의 감염을 확인하였고, 8월 25일에 남아있는 15개의 샘플 중 11개의 샘플에서 추가 감염을 확인하였다. Fig. 1(b)에 1열에 재배되고 있는 30개의 묘목을 3열로 나누어 도식화 하였고, 7월 27일에 감염이 확인된 개체를 빨간색, 8월 25일에 추가로 감염이 확인된 개체를 파란색, 8월 25일까지 감염되지 않은 개체를 검은색으로 나타내었다.
다중분광 영상 처리
취득한 개별 영상은 Pix4D mapper(Pix4D S.A., Switzerland)를 이용하여 접합하고 pansharpening 처리 후 QGIS(Quantum GIS, USA)로 정합하였다. ENVI 5.3(Exelis Visual Information Solution Inc., USA)에서 GNDVI-NDVI를 이용하여 식생과 배경을 분리(Fig. 2)하고 개체 별 반사값을 추출하였다.

밴드의 반사값은 환경변화에 민감하기 때문에 정규화 식생지수 NDVI, GNDVI, NDRE, PRI, 단순비 식생지수 RVI, GRVI, 단순계산 식생지수 DVI, 변형된 식생지수 OSAVI, TCARI로 총 9개의 식생지수(Table 2)를 산출하여 사용하였다.
Table 2.
Vegetation Indices (VIs).
| Name | Claculation | Reference |
| NDVI | (Huang et al., 2021) | |
| GNDVI | (Hunt et al., 2008) | |
| GRVI | (Avola et al., 2019) | |
| RVI | (Basso et al., 2004) | |
| DVI | (Basso et al., 2004) | |
| NDRE | (Boiarskii and Hasegawa., 2019) | |
| PRI | (Lee et al., 2021) | |
| OSAVI | (Zhang et al., 2019) | |
| TCARI | (Zhang et al., 2019) |
시들음병에 감염된 고추에서 반사값을 추출하여 시들음병의 감염여부에 대한 분석을 진행하려 하였으나 고사된 고추가 많아 반사값을 추출할 수 없었다. 따라서, 시들음병이 관측된 7월과 8월의 영상이 아닌 6월과 7월의 영상에서 추출된 묘목의 위치에 대한 각각의 반사값으로 산출된 식생지수를 이용하여 시들음병의 조기 검출 가능성을 검토하였다.
Table 3과 같이 6월 28일 영상의 식생지수로 7월 27일에 감염되지 않은 고추(15샘플)와 감염된 고추(15샘플)를 분류하는 경우를 Case 1, 추가로 7월 27일 영상의 식생지수로 8월 25일에 감염되지 않은 고추(4샘플)와 감염된 고추(11샘플)를 분류하는 경우를 Case 2, Case 2에서 감염되지 않은 데이터를 제외한 경우를 Case 3으로 구분하여 분석을 진행하였다.
Table 3.
Sampling numbers of each case.
통계분석
통계분석은 Jupyter Notebook 6.3.0(Python 3.8.8, Project Jupyter, USA)을 이용하였고 이상치는 IQR 방식(Yang et al., 2019)으로 제거하였다. 머신러닝 분류 알고리즘 중 가장 가까운 이웃들의 클래스를 참조하여 분류를 수행하는 K-Nearest Neighbor (KNN, Laaksonen and Oja, 1996), 초평면을 통해 데이터를 최대한 분리하는 경계선을 찾아내는 Support Vector Machine(SVM, Brereton and Lloyd, 2010), 입력 변수와 결과 변수 간의 선형 관계를 기반으로 특정 범주에 속할 확률을 예측하는 Logistic Regression (LR, Khurshid and Khan, 2014)을 이용하여 상관관계분석(Schober et al., 2018)을 통해 나열한 변수를 후진소거법으로 제거하면서 모델을 작성하였다. Calibration과 validation의 데이터 비율은 8:2, 7:3, 6:4 3가지로 설정하였고 평가지표로는 accuracy, precision, recall, F1-score를 사용하였다(Haque et al., 2022). 모델의 성능을 시각적으로 확인하기 위해 결과를 confusion matrix, precision-recall curve(P-R curve), ROC curve로 시각화 하였다. P-R curve는 양성(positive) 예측 중 참 양성(true positive)의 비율을 면적으로 평가한다(Saito and Rehmsmeier, 2015). 반면, 모델의 전체적인 성능을 평가하는 ROC curve(Saito and Rehmsmeier, 2015)는 P-R curve에 비해 음성(negative) 클래스에 영향을 더 받는다. 본 연구에서는 검증 및 일반화 성능을 고려하여 validation accuracy가 가장 높은 모델을 가장 좋은 모델로 판단하였고, validation accuracy가 동일할 때에는 실제 방제에서 중요한 지표인 양성(감염)인데 음성(비감염)이라고 예측한 False Negative(FN)를 사용하여 산출되는 validation recall이 더 높은 모델을 좋은 모델로 판단하였다.
Results and Discussion
Case 1에 대한 분류 모델
6월 28일 영상의 식생지수로 7월 27일에 감염되지 않은 고추(15샘플)와 감염된 고추(15샘플)를 분류하는 Case 1 모델의 비감염개체와 감염개체의 평균, 표준편차 및 샘플 수를 Table 4에 나타내었다. Case 1의 t-test를 진행한 결과, NDVI에서만 유의미한 차이가 나타났고 나머지 식생지수에서는 유의미한 차이가 나타나지 않았다. NDVI에서 비감염샘플이 감염샘플보다 유의미하게 큰 것으로 나타났다.
Table 4.
Basic statistics of Case 1 after outlier elimination.
| VIs | Mean ± S.D | |
| Non-infected | Infected | |
| NDVI | 0.917 ± 0.004a1 (15) | 0.912 ± 0.008b (13) |
| GNDVI | 0.805 ± 0.006 (14) | 0.801 ± 0.010 (12) |
| GRVI | 9.278 ± 0.334 (14) | 9.098 ± 0.527 (12) |
| RVI | 23.24 ± 1.176 (15) | 21.86 ± 2.141 (13) |
| DVI | 0.569 ± 0.023 (15) | 0.549 ± 0.022 (13) |
| NDRE | 0.498 ± 0.009 (14) | 0.490 ± 0.015 (13) |
| PRI | -0.498 ± 0.010 (14) | -0.488 ± 0.012 (13) |
| OSAVI | 0.846 ± 0.009 (15) | 0.836 ± 0.013 (13) |
| TCARI | -0.107 ± 0.024 (13) | -0.089 ± 0.038 (12) |
Case 1의 KNN, SVM, LR모델 중 가장 높은 성능을 나타낸 각 모델의 결과를 Table 5에 나타내었다.
Table 5.
Results of each classification model in Case 1.
KNN에서 validation의 accuracy와 recall이 가장 높은 값을 나타내어 PRI, OSAVI, DVI, NDVI, RVI, TCARI, NDRE, GNDVI를 독립변수로 사용한 7:3 비율의 KNN모델이 calibration에서 accuracy = 0.765, precision = 0.778, recall = 0.778, F1-score = 0.778, validation에서 accuracy = 0.750, precision = 1.000, recall = 0.600, F1-score = 0.750의 성능으로 가장 좋은 모델로 판단하였다. KNN모델의 validation confusion matrix, P-R curve, ROC curve를 Fig. 3에 나타내었다.
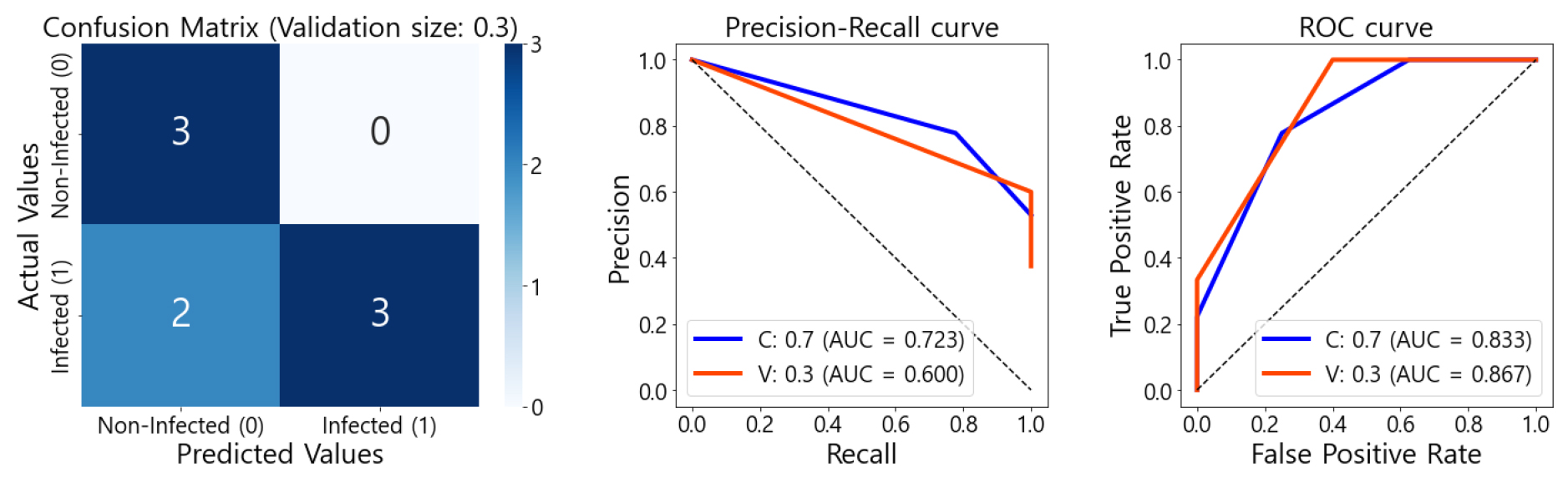
Validation confusion matrix를 확인한 결과, 방제에서 중요한 지표인 실제로 병에 걸렸지만 병에 걸리지 않았다고 판단한 데이터인 False Negative(FN)가 2개 존재하여 0.600의 낮은 recall 값을 나타내었다. Case 1 모델의 validation에서 P-R curve의 Area Under Curve(AUC)가 0.600의 면적을 나타낸 것으로 보아 감염개체(양성)의 탐지에 대한 검증 성능이 낮고 ROC curve의 AUC는 calibration과 validation에서 각각 0.833, 0.867의 면적을 나타낸 것으로 보아 비감염개체(음성) 클래스에 대한 탐지 성능은 상대적으로 높은 것으로 판단된다.
Case 2에 대한 분류 모델
Case 1에 7월 27일 영상의 식생지수로 8월25일에 감염되지 않은 고추(4샘플)와 추가로 감염된 고추(11샘플)를 추가한 Case 2의 비감염개체와 감염개체의 평균, 표준편차, 이상치를 제거한 샘플 수를 Table 6에 나타내었다. Case 2의 t-test를 진행한 결과, 모든 식생지수에서 유의미한 차이를 나타내었으며, NDVI, GNDVI, GRVI, RVI, DVI, NDRE, OSAVI에서 비감염개체가 감염개체보다, PRI, TCARI에서 감염개체가 비감염개체보다 유의미하게 더 크다고 나타났다.
Table 6.
Basic statistics of Case 2 after outlier elimination.
| VIs | Mean ± S.D | |
| Non-infected | Infected | |
| NDVI | 0.900 ± 0.033a1 (19) | 0.871 ± 0.047b (24) |
| GNDVI | 0.791 ± 0.028a1 (18) | 0.768 ± 0.041b (21) |
| GRVI | 8.713 ± 1.106a1 (18) | 7.890 ± 1.482b (21) |
| RVI | 20.73 ± 4.986a1 (19) | 16.61 ± 5.989b (24) |
| DVI | 0.526 ± 0.086a1 (19) | 0.457 ± 0.103b (24) |
| NDRE | 0.490 ± 0.019a1 (18) | 0.471 ± 0.027b (23) |
| PRI | -0.460 ± 0.071b (18) | -0.422 ± 0.081a1 (22) |
| OSAVI | 0.817 ± 0.056a1 (19) | 0.769 ± 0.074b (24) |
| TCARI | -0.054 ± 0.097b (17) | 0.000 ± 0.108a1 (22) |
Case 2에서 작성된 각 KNN, SVM, LR모델 중 가장 높은 성능을 나타낸 모델의 결과를 Table 7에 나타내었다.
Table 7.
Results of each classification model in Case 2.
KNN과 SVM의 validation accuracy는 동일하였지만 SVM이 더 높은 validation recall이 값을 나타내어 NDRE, GNDVI, DVI, NDVI, OSAVI를 독립변수로 사용한 8:2 비율의 SVM모델이 calibration에서 accuracy = 0.655, precision = 0.688, recall = 0.688, F1-score = 0.688, validation에서 accuracy = 0.778, precision = 0.714, recall = 1.000, F1-score = 0.833의 성능으로 가장 좋은 모델로 판단하였다. SVM모델의 validation confusion matrix, P-R curve, ROC curve를 Fig. 4에 나타내었다.
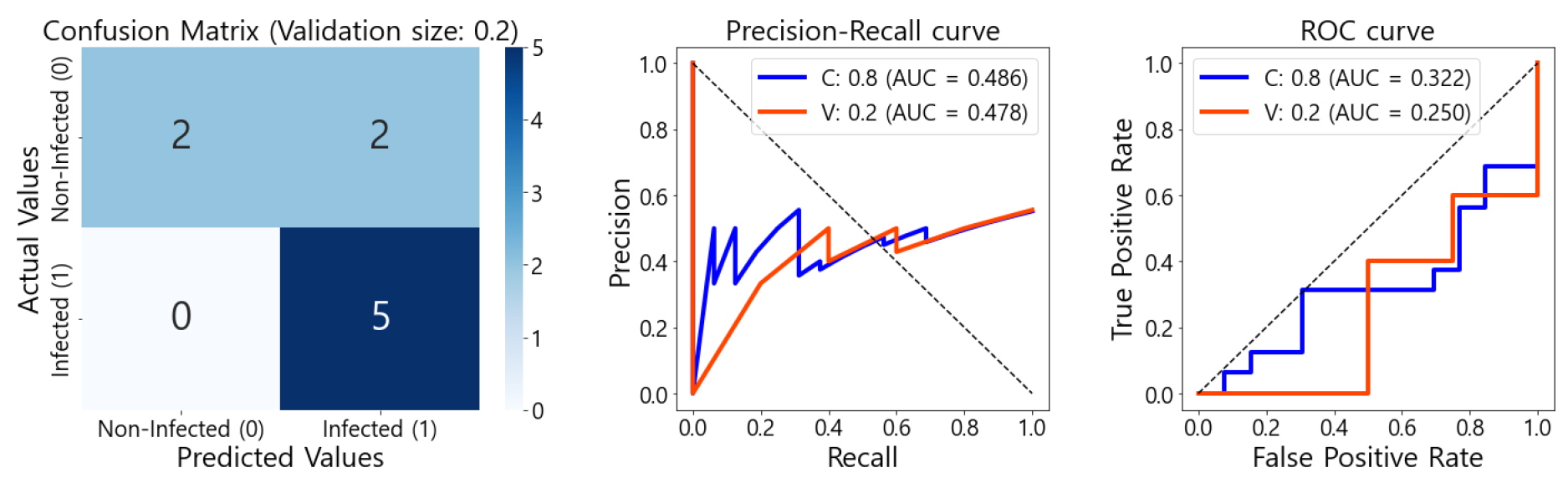
Validation confusion matrix를 확인한 결과, 실제로 병에 걸렸지만 병에 걸리지 않았다고 판단한 데이터인 FN이 0개로 1.000의 높은 recall 값을 나타내었다. 그러나 P-R curve의 AUC가 calibration과 validation에서 각각 0.486와 0.478, ROC curve에서는 0.322와 0.250의 좁은 면적을 나타내었다. 이는 양성(감염) 클래스는 모두 예측한 반면, 음성(비감염) 클래스는 절반만 예측하여 클래스에 따른 분류 성능의 불균형이 발생하였기 때문으로 판단된다.
Case 3에 대한 분류 모델
Case 2에서 감염되지 않은 데이터를 제외한 Case 3 모델을 작성하였고, 비감염개체와 감염개체의 평균, 표준편차, 이상치를 제거한 샘플 수를 Table 8에 나타내었다. Case 3의 t-test를 진행한 결과, Case 2와 동일하게 모든 식생지수에서 유의미한 차이를 나타내었으며, NDVI, GNDVI, GRVI, RVI, DVI, NDRE, OSAVI에서 비감염개체가 감염개체보다, PRI, TCARI에서 감염개체가 비감염개체보다 유의미하게 더 크다고 나타났다.
Table 8.
Basic statistics of Case 3 after outlier elimination.
| VIs | Mean ± S.D | |
| Non-infected | Infected | |
| NDVI | 0.917 ± 0.004a1 (15) | 0.871 ± 0.047b (24) |
| GNDVI | 0.805 ± 0.006a1 (14) | 0.768 ± 0.041b (21) |
| GRVI | 9.278 ± 0.334a1 (14) | 7.890 ± 1.482b (21) |
| RVI | 23.24 ± 1.176a1 (15) | 16.61 ± 5.989b (24) |
| DVI | 0.569 ± 0.023a1 (15) | 0.457 ± 0.103b (24) |
| NDRE | 0.498 ± 0.009a1 (14) | 0.471 ± 0.027b (23) |
| PRI | -0.498 ± 0.010b (14) | -0.422 ± 0.081a1 (22) |
| OSAVI | 0.846 ± 0.009a1 (15) | 0.769 ± 0.074b (24) |
| TCARI | -0.107 ± 0.024b (13) | 0.000 ± 0.108a1 (22) |
Case 3에서 작성된 각 KNN, SVM, LR모델 중 가장 높은 성능을 나타낸 모델의 결과를 Table 9에 나타내었다.
Table 9.
Results of each classification model in Case 3.
SVM에서 validation의 accuracy와 recall이 가장 높은 값을 나타내어 DVI, TCARI, RVI를 독립변수로 사용한 7:3 비율의 KNN모델이 calibration에서 accuracy = 0.783, precision = 0.733, recall = 0.917, F1-score = 0.815, validation에서 accuracy = 0.909, precision = 0.833, recall = 1.000, F1-score = 0.909의 성능으로 가장 좋은 모델로 판단하였다. KNN모델의 validation confusion matrix, P-R curve, ROC curve를 Fig. 5에 나타내었다.
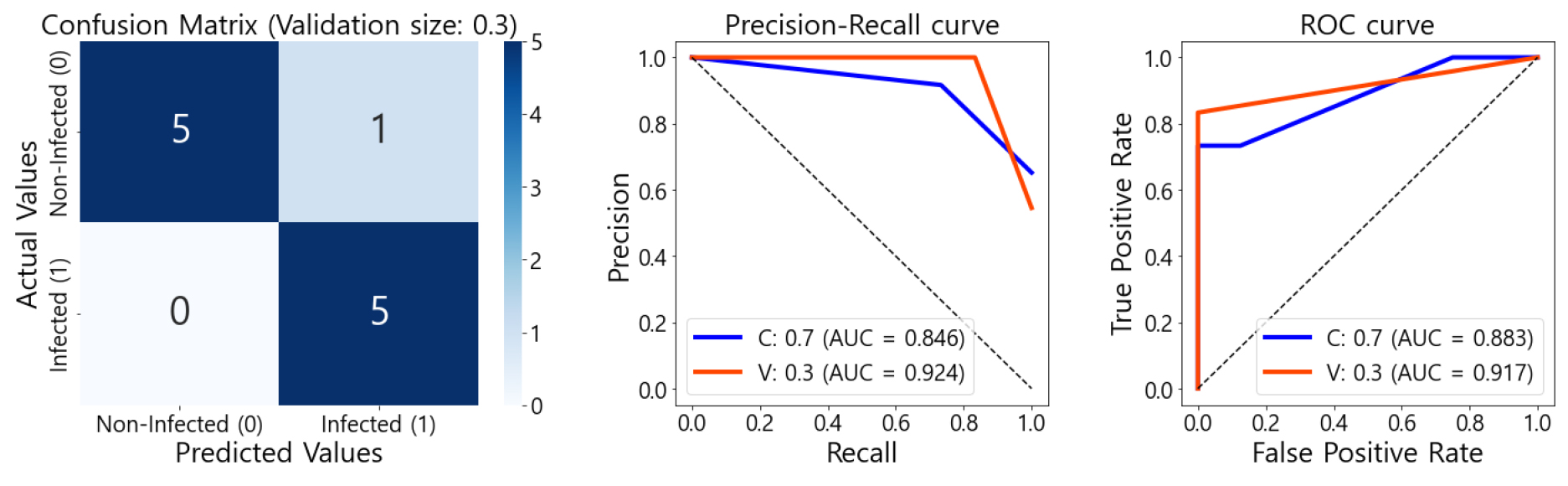
Validation confusion matrix를 확인한 결과, 실제로 병에 걸렸지만 병에 걸리지 않았다고 판단한 데이터인 FN이 0개로 1.000의 높은 recall 값을 나타내어 해당 모델이 실제 방제에 가장 적합할 것으로 사료된다. P-R curve의 AUC가 calibration과 validation에서 각각 0.846와 0.924, ROC curve에서는 0.883와 0.917의 면적을 나타내어 양성(감염)과 음성(비감염) 클래스 모두에 대해서 높은 탐지 성능을 나타내는 것으로 판단된다.
고추 시들음병 분류 모델에 대한 고찰
시들음병 감염여부에 따른 t-test에서 Case 2와 Case 3의 가장 좋은 모델에 사용된 식생지수의 p-value를 비교하였을 때 Case 2(NDRE; p = 0.043, GNDVI; p = 0.031, DVI; p = 0.006, NDVI; p = 0.007, OSAVI; p = 0.019)보다 Case 3(DVI; p = 0.0004, TCARI; p = 0.002, RVI; p = 0.002)에서 사용된 식생지수가 전체적으로 더 낮은 p-value를 나타냈다. 이는 7월 27일 영상의 데이터를 모두 추가한 Case 2보다 8월 25일에 감염되지 않은 정상개체를 제외한 Case 3에서 시들음병 감염 여부에 따른 식생지수의 차이가 통계적으로 더 유의미하다는 것을 나타낸다. 이러한 데이터의 차이로 인해 Case 2 모델(Accuracy_C = 0.655, Precision_C = 0.688, Recall_C = 0.688, F1-score_C=0.688, Accuracy_V = 0.778, Precision_V = 0.714, Recall_V = 1.000, F1-score_V=0.833)보다 Case 3 모델(Accuracy_C = 0.783, Precision_C = 0.733, Recall_C = 0.917, F1-score_C=0.815, Accuracy_V = 0.909, Precision_V = 0.833, Recall_V = 1.000, F1-score_V=0.909)이 더 높은 성능을 나타낸 것으로 판단된다.
세 가지 머신러닝 분류 알고리즘 중 KNN이 가장 높은 성능을 나타낸 것은 본 연구에 사용된 데이터가 40개 미만으로 적었으며, KNN이 데이터의 복잡한 구조를 학습할 필요 없이 인접한 샘플 간의 거리를 기반으로 단순한 방식으로 분류를 수행하여 적은 데이터의 분석에 더 유리하기 때문인 것으로 판단된다. 따라서 시들음병의 조기탐지 가능성에 대한 체계적인 연구를 위해서는 추가적인 데이터 확보를 기반으로 한 다양한 머신러닝 기법의 적용과 시계열 및 다년간의 영상 데이터의 수집이 필요하다고 판단된다. 또한 본 연구에 사용된 데이터의 샘플 수가 제한적이고, 단순한 훈련과 검증의 데이터 분할 방법으로 인해 과적합의 가능성이 있다. 따라서 후속 연구에서는 현장조사를 통해 시들음병 감염여부를 판단한 데이터뿐만 아니라 시계열 영상을 기반으로 생육지수의 변화를 이용한 병의 감염여부를 판단한 데이터를 다수 추가하여 모델을 개발 및 개선한 후 k-fold, leave one out 등의 다양한 교차 검증을 수행함으로써 일반화 성능을 검증할 예정이다.
Conclusion
본 연구는 다중분광 영상으로부터 추출된 반사값을 바탕으로 식생지수를 산출하고, 이를 머신러닝 분류 알고리즘에 적용하여 시들음병의 발생여부를 조기에 탐지하는 모델을 작성하여 비교 및 분석하였다.
6월 28일 영상의 식생지수로 7월 27일에 감염되지 않은 고추(15샘플)와 감염된 고추(15샘플)를 분류하는 Case 1에서는 PRI, OSAVI, DVI, NDVI, NDVI, RVI, TCARI, NDRE, GNDVI을 독립변수로 사용한 7:3 비율의 KNN모델이 calibration에서 accuracy = 0.765, precision = 0.778, recall = 0.778, F1-score = 0.778, validation에서 accuracy = 0.750, precision = 1.000, recall = 0.600, F1-score = 0.750의 성능을 나타내어 가장 좋은 모델로 선택되었으며, validation confusion matrix를 확인한 결과 방제에서 중요한 지표인 실제로 병에 걸렸지만 병에 걸리지 않았다고 판단한 데이터인 false negative(FN)가 2개 존재하였다. P-R curve의 AUC가 Calibration과 validation에서 각각 0.723와 0.600, ROC curve에서는 각각 0.833와 0.867의 면적을 나타내었다.
Case 1에 7월 27일 영상의 식생지수로 8월25일에 감염되지 않은 고추(4샘플)와 추가로 감염된 고추(11샘플)를 추가한 Case 2에서는 NDRE, GNDVI, DVI, NDVI, OSAVI를 독립변수로 사용한 8:2 비율의 SVM모델이 calibration에서 accuracy = 0.655, precision = 0.688, recall = 0.688, F1-score = 0.688, validation에서 accuracy = 0.778, precision = 0.714, recall = 1.000, F1-score = 0.833의 성능을 나타내어 가장 좋은 모델로 선택되었으며, validation confusion matrix를 확인하였을 때 FN이 존재하지 않아 1.000의 recall 값을 나타내었다. P-R curve의 AUC가 Calibration과 validation에서 각각 0.486와 0.478, ROC curve에서는 각각 0.322와 0.250의 면적을 나타내었다.
Case 2에서 감염되지 않은 데이터를 제외한 Case 3에서는 DVI, TCARI, RVI를 독립변수로 사용한 7:3 비율의 KNN모델이 calibration에서 accuracy = 0.783, precision = 0.733, recall = 0.917, F1-score = 0.815, validation에서 accuracy = 0.909, precision = 0.833, recall = 1.000, F1-score = 0.909의 성능을 나타내어 가장 좋은 모델로 선택되었으며, validation confusion matrix를 확인하였을 때 FN이 존재하지 않아 1.000의 recall 값을 나타내었다. P-R curve의 AUC가 calibration과 validation에서 각각 0.846와 0.924, ROC curve에서는 각각 0.883와 0.917의 면적을 나타내었다.
세 가지 경우 중에 Case 3의 KNN모델이 validation 가장 높은 accuracy와 recall을 나타내었고 validation의 confusion matrix에서 FN이 0개이며, P-R curve와 ROC curve에서 모두 가장 넓은 AUC를 나타내었기 때문에 실제 시들음병 탐지 및 방제에서 가장 유용할 것이라 사료된다.
본 연구에서 개발된 모델은 실제 농가에서 고추 시들음병을 조기에 발견하여 질병 확산을 효과적으로 억제하고 피해를 최소화함으로써 고추의 생산량 증대와 농가 소득 향상에 기여할 수 있고, 불필요한 농약 사용을 줄임으로써 환경 친화적 농업 실현과 생산 비용 절감을 도모할 수 있을 것으로 사료된다. 또한, 데이터의 추가를 통해 모델 성능이 향상된 것을 확인하였으므로, 앞으로 더 많은 고추 시들음병 데이터의 수집을 통해 모델의 성능을 더욱 개선할 수 있을 것으로 기대된다.
