

Introduction
Materials and Methods
데이터 셋 선정
분석 모델 설정
모델 성능 지표
Results and Discussion
데이터 분석 결과 및 시각화
모델 성능 검증
Conclusions
Introduction
농업 부문은 사물인터넷(IoT), 인공지능(AI), 빅데이터 분석 등의 스마트 농업 기술을 도입함으로써 생산성과 지속 가능성을 향상시키는 방향으로 변화하고 있다(Wolfert et al., 2017). 스마트 농업은 센서 네트워크와 자동화 기술을 활용하여 작물 생육 환경을 최적화하고, 환경 영향을 줄이며, 수확량 예측을 개선하는 데 기여한다. 온도, 습도, 토양 수분과 같은 주요 농업 변수를 실시간으로 모니터링함으로써 데이터 기반의 의사결정이 가능해진다(Klerkx et al., 2019; Ahmed et al., 2025a).
스마트 농업의 중요한 응용 분야 중 하나는 보호 원예(protected horticulture)로, 제어된 환경을 통해 작물의 생산성을 극대화할 수 있다. 온실에서 널리 재배되는 작물인 오이는 최적의 생육을 위해 정밀한 모니터링이 필수적이다. 그러나 기존의 수작업 기반 모니터링 방법은 노동 집약적이며 오류 발생 가능성이 높아, 자동화된 데이터 기반 접근 방식이 필수적이다(Jin et al., 2020; Lee et al., 2023). 스마트 농업 빅데이터 플랫폼은 구조화된 데이터와 비구조화된 농업 데이터를 수집하여, 정밀 농업을 향상시키는 AI 기반 예측 모델 개발의 기회를 제공한다.
농업 데이터의 가용성이 증가함에 따라, AI 기반 접근법, 특히 딥러닝은 작물 생육 모델링, 질병 탐지, 수확량 예측 등의 분야에서 강력한 도구로 부상하고 있다(Kamilaris & Prenafeta-Boldú, 2018; Kim et al., 2023). 딥러닝 아키텍처 중 순환 신경망(Recurrent Neural Networks, RNNs), 합성곱 신경망(Convolutional Neural Networks, CNNs), 트랜스포머(Transformer) 모델은 시계열 센서 데이터를 분석하는 데 있어 우수한 성능을 보였다(Rehman et al., 2019). Gated Recurrent Units(GRU) 및 Long Short-Term Memory(LSTM) 모델은 연속적인 농업 데이터에서 시간적 종속성을 효과적으로 포착할 수 있으며(Hochreiter & Schmidhuber, 1997), 이미지 처리에 주로 사용되던 CNN은 1차원 시계열 데이터에서도 국소적(local) 특징을 추출하는 데 성공적인 성과를 보였다(Kiranyaz et al., 2021). 최근에는 자연어 처리(NLP) 분야에서 개발된 트랜스포머 기반 아키텍처가 농업 분야에서도 주목받고 있으며, 이는 장기 의존성(long-range dependencies) 및 복잡한 특성 간의 상호작용을 효과적으로 처리할 수 있기 때문이다(Vaswani et al., 2017; Lim et al., 2021).
여러 연구에서 딥러닝을 활용하여 작물 생육 예측 및 수확량 추정에 성공적으로 적용한 사례가 보고되고 있다. 날씨와 토양 조건에 따른 작물 수확량 예측에는 LSTM 기반 모델이, 식물 스트레스 탐지에는 하이퍼스펙트럴 이미징(hyperspectral imaging)을 활용한 CNN 모델이 사용되고 있다. 그러나 이러한 발전에도 불구하고, 농업 시계열 데이터의 변동성과 복잡성은 모델 개발에 있어 여전히 도전 과제로 남아 있다. 예측 성능은 데이터의 품질과 구조에 크게 의존하는데, 농업 데이터는 높은 변동성, 결측치, 그리고 노이즈를 포함하는 경우가 많아 정확도에 상당한 영향을 미칠 수 있다(Boulent et al., 2019; Ahmed et al., 2025b). 또한, 센서 오작동, 불규칙한 데이터 수집 간격, 환경적 변화와 같은 요인들이 학습 과정을 더욱 복잡하게 만든다.
시계열 데이터를 처리하는 데 있어 주요한 도전 과제는 시간적 종속성(temporal dependencies)을 유지하면서도 데이터셋이 실제 환경을 대표할 수 있도록 보장하는 것이다(Zhou et al., 2021). 이미지 기반 모델과 달리, 시계열 모델은 샘플 간의 독립성이 보장되지 않으며, 연속적인 패턴과 추세를 효과적으로 식별하기 위해 순차적 무결성(sequential integrity)이 필수적이다. 전통적인 검증 기법인 k-폴드 교차 검증(k-fold cross-validation)은 시계열 데이터에 적합하지 않은데, 이는 데이터 샘플을 무작위로 섞을 경우 데이터 누출(data leakage)이 발생하고 비현실적인 예측 결과를 초래할 수 있기 때문이다(Berrar, 2019). 이러한 문제를 해결하기 위해, 데이터셋 간 샘플 섞기를 비활성화하여 모델이 학습 과정에서 시간적 순서를 유지할 수 있도록 하는 방법이 제안되었다.
그러나 검증 방법이 개선되더라도, 모델의 일반화 성능(generalizability), 데이터 불균형 및 일관성 문제, 그리고 연산 효율성(computational efficiency)과 같은 도전 과제는 여전히 해결해야 할 과제로 남아 있다. AI 기반 농업 모델이 발전함에도 불구하고, 일반화 성능은 주요한 한계점으로 지적되고 있으며, 특정 농장에서 수집된 데이터로 학습된 모델이 다른 환경 조건에서는 성능이 저하될 가능성이 높다(You et al., 2017). 이러한 문제를 해결하기 위해서는 높은 예측 정확도를 유지하면서도 다양한 농업 환경에 적응할 수 있는 모델 개발이 필요하다.
본 연구의 목적은 국내 스마트농업 공공 빅데이터 플랫폼에 적재된 시계열 생육 및 환경 데이터를 기반으로 오이 과중 예측을 위한 최적의 딥러닝 모델을 개발하고, 모델별 예측 성능을 비교·분석함으로써 데이터 활용 가능성을 평가하는 데 있다. 이를 위해 GRU, 1D-CNN, Transformer 모델을 동일한 조건 하에서 학습시켜 예측 정확도를 비교하고, 시계열 농업 데이터의 복잡성과 현실성을 반영한 전처리 및 교차검증 기법을 적용하였다. 최적의 인공지능 모델은 평균 절대 오차(MAE)와 결정계수(R2)를 기준으로 평가되었으며, 데이터의 유용성은 모델 적용 결과의 예측 신뢰성과 실질적 활용 가능성을 중심으로 논의하였다.
Materials and Methods
본 연구를 수행하기 위해 스마트 농업 공공 빅데이터 플랫폼(Smart Agriculture Public Big Data Platform)의 정보를 활용하여 데이터셋을 구축하였으며, 특히 구조화된 시계열 데이터를 이용하여 스마트 농업 연구에서의 실용성을 평가하였다. 본 연구에서는 보호 원예(protected horticulture) 부문에서 연중 재배가 가능한 작물로서 오이를 대상 작물로 선정하였다. 환경 데이터와 생육 데이터를 통합하여 오이의 생육을 예측함으로써, 균일한 과중(fruit weight)을 유지하고 최적의 생육 조건을 보장하는 것을 목표로 하였다. 정확한 예측을 달성하기 위해, 본 연구에서는 잎 길이(leaf length), 잎 개수(leaf count), 잎 너비(leaf width)와 같은 생육 지표와 내부 온도(internal temperature), 상대 습도(relative humidity), 일사량(solar radiation)과 같은 환경 요인을 결합하여 모델을 구축하였다. 과중은 오이의 최종 생산물인 열매의 크기와 무게를 나타내는 대표적인 지표로, 본 연구에서는 생육 정보(엽장, 엽수, 엽폭 등)와 환경 정보(내부 온도, 내부 상대 습도, 일사량 등)를 결합하여 오이의 생육 상태를 예측하고자 하였다. 엽면적, 광합성 활성 등 생장 조건은 과중의 증가에 기여하며 이는 작물의 중량이 성장과 관련된 물리적, 생리적 매개변수를 나타내어 결과적으로 수확량 증대로 이어질 수 있다고 한다(Galvan et al., 2021; Islam et al., 2023). 이를 통해 오이 생육에서 주요한 지표로 사용되는 엽수, 엽면적과 같은 데이터를 통해 과중을 예측할 수 있다는 가설을 가지고 총 3가지의 분석 모델 개발을 진행하였다. Fig. 1은 위 내용에 따른 전체적인 개발 모식도를 나타낸다. 전체 연구 과정은 데이터 전처리(data preprocessing), 모델링(modeling), 성능 평가(performance evaluation)의 세 가지 주요 단계로 구성된다. 첫 번째 단계에서는 시계열 데이터 수집을 위한 데이터 전송(data transmission), 결측치 발생 시 데이터 보간(data interpolation), 사분위 범위(Interquartile Range, IQR) 기반 이상치 제거(outlier elimination), 그리고 (사용한 정규화 방법 추가 필요)을 활용한 데이터 스케일 변환(scaling)이 수행되었다. 두 번째 단계인 모델링에서는 GRU, 1차원 합성곱 신경망(1D-CNN), 트랜스포머(Transformer)와 같은 세 가지 시계열 학습 모델을 적용하였으며, 상관 분석(correlation analysis) 및 교차 검증(cross-validation)을 통해 모델 성능을 비교하였다. 마지막으로, 모델 성능을 평가하여 최적의 모델을 선정하였다.
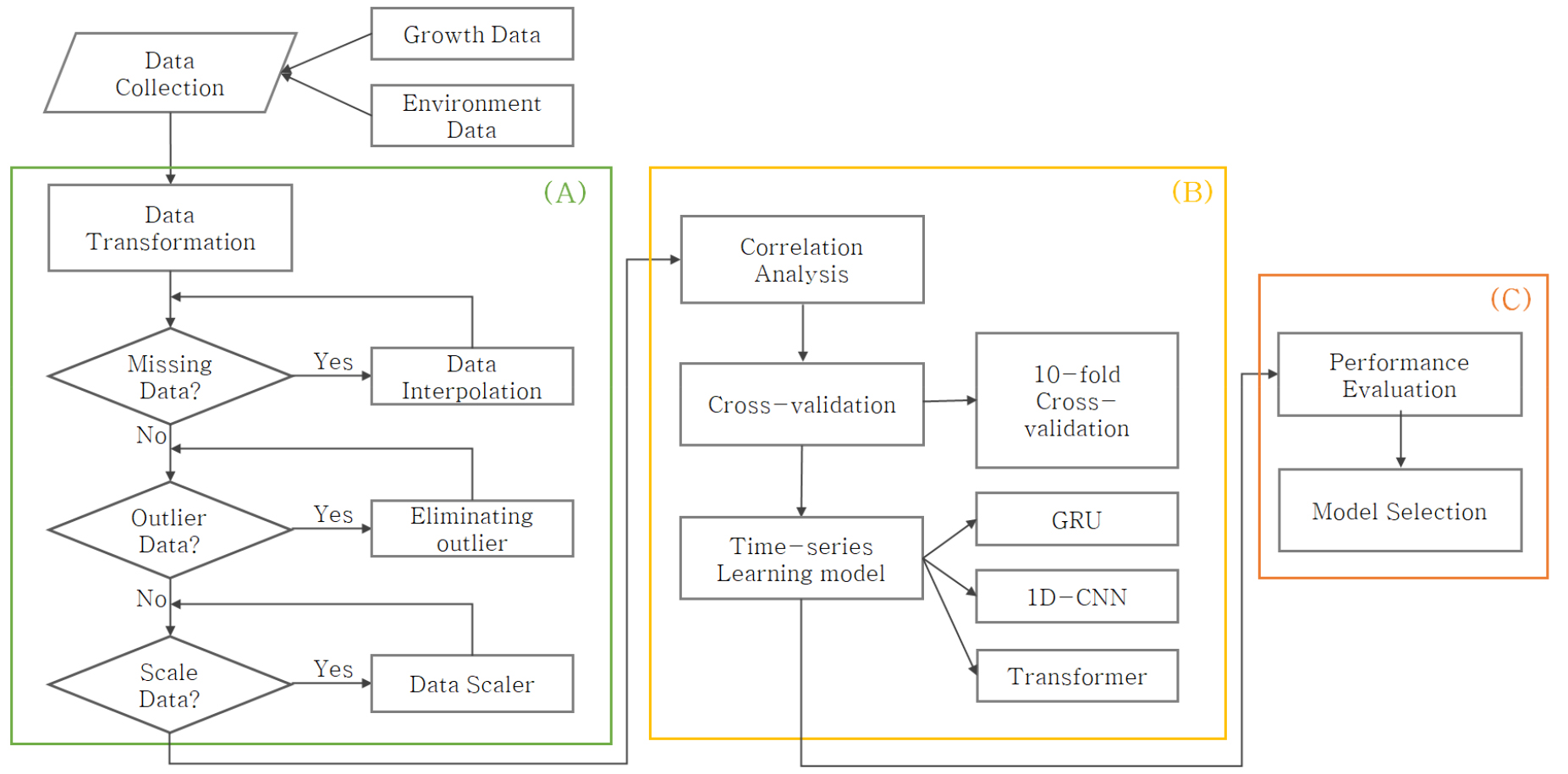
데이터 셋 선정
대구광역시에 위치한 동일한 농가에서 수집된 두작기의 데이터를 활용하였으며 주요 정보는 Table 1을 통해 확인할 수 있다. 데이터는 보다 정확한 생육 측정을 위해 개체 번호를 부여하여 관리되었으며, 스마트팜 농가로부터 매일 같은 시각에 측정되었지만 각각의 데이터베이스로 관리되고 있던 생육정보와 환경 정보를 결합하여 사용하였다. 작물 개체의 생장 변화를 분석하기 위해 조사일시와 작물 개체 번호가 같을 시에만 결합하였으며 데이터 손실이 많은 변수 즉, 결측값이 많은 변수(감우, 급액 EC, 급액 pH 등)는 제외하였다. 각 변수의 설명과 단위 등 요약표는 Table 2에 나타냈다.
Table 1.
Key information of the dataset used in this study.
| Category | Location | Growing Season | Planting Month |
| Dataset 1 | Daegu | March 2021 to July 2021 | February 2021 |
| Dataset 2 | Daegu | November 2022 to April 2023 | October 2022 |
Table 2.
Description of the dataset variables used in this study
1201행 X 16열의 데이터를 사용하여 모델 학습을 진행하였는데, 본 연구에서는 생육 정보를 더욱 상세히 분석하기 위해 가지고 있는 변수들을 서로 결합하여 유의미한 변수를 추가 생성한 것이다. 첫째로 생성한 변수는 엽수와 엽폭의 데이터를 활용하여 엽면적이다. 엽면적은 광합성 효율과 관련이 깊어 환경 조건이 엽면적에 미치는 영향을 분석할 수 있을 것이라 판단하였으며 이때 잎의 크기를 보다 직관적으로 파악할 수 있도록 식물학적 관점을 통해 타원형으로 가정하여 아래 식 (1)을 통해 계산하였다.
두 번째로, 위 내용과 같이 생성된 엽면적과 일사량을 통해 작물이 얼마나 효율적으로 광합성을 수행하는지 확인하고자 면적당 일사량을 아래 식 (2)과 같이 계산하였다.
마지막으로 생육 효율성 변수를 생성하여 과중과 환경 변수의 비율을 계산하였다. 이는 작물의 생육이 환경 변화에 얼마나 민감하게 반응하는지를 확인하고자 세가지의 환경변수 CO2, 내부온도, 내부습도를 사용하여 아래 식과 같이 생육 효율성 변수를 생성하였으며 이때 X는 세가지 환경변수를 나타낸다. 분모에 1을 더해 환경변수가 0일 경우 오류 발생을 방지하였다.
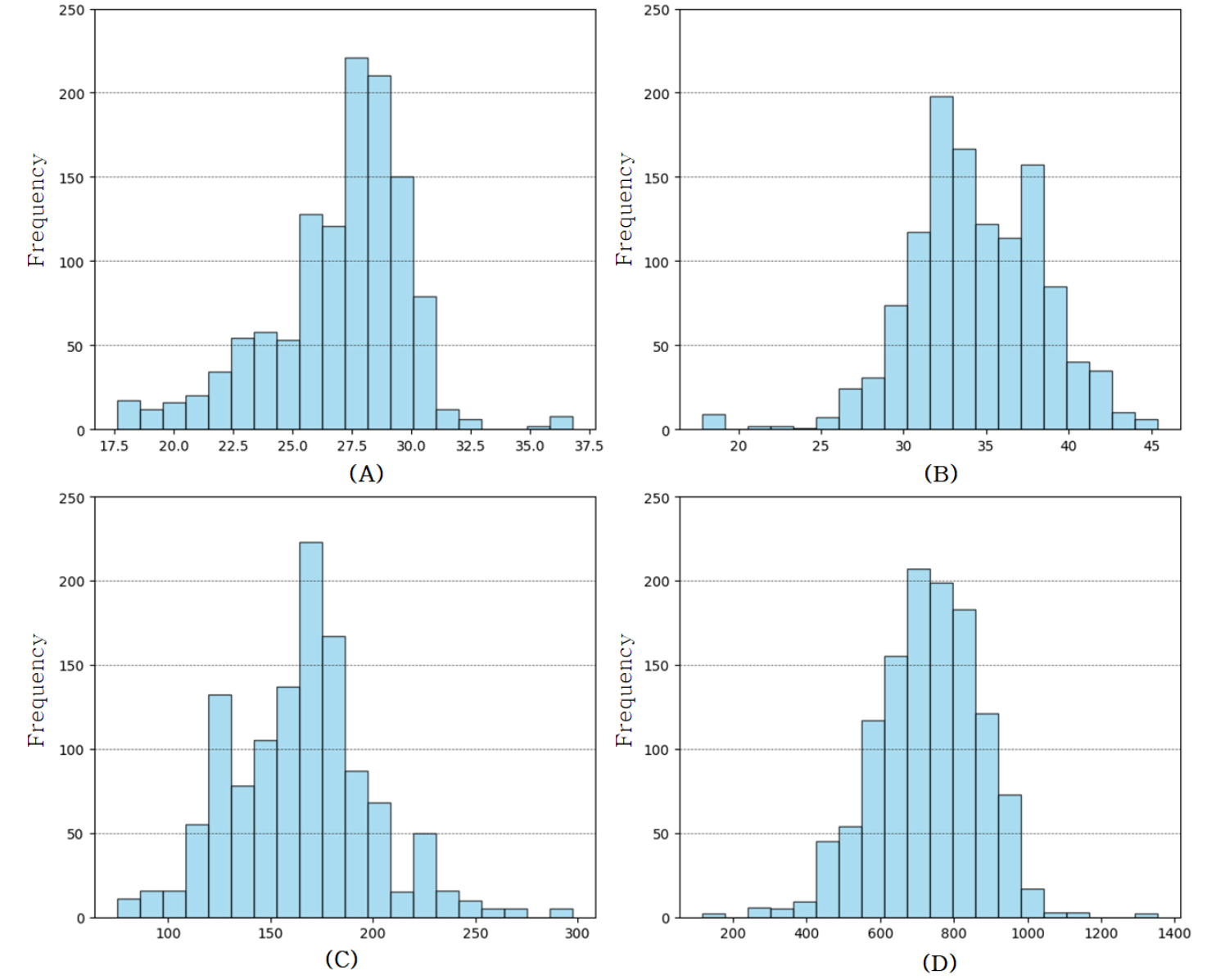
본 연구에서는 스마트농업에서 사용된 주요 변수들의 분포를 파악하기 위해 히스토그램을 작성하였다. 분석 대상 변수는 엽장, 엽폭, 과중, 엽면적 총 4가지이며, 이를 통해 데이터의 분포 특성과 중심 경향을 확인하였다.
Fig. 2를 통해 확인할 수 있듯이, 분석 결과 엽장은 평균 약 26.92 cm, 표준편차 2.93로, 데이터가 정규분포에 가까운 형태를 보였다. 엽폭은 평균 약 34.36 cm, 표준편차 4.00로 나타났으며, 일부 변동성이 관찰되었다. 과중은 평균 약 165.30 g, 표준편차 34.67로 나타났으며, 100 g 이하 및 250 g 이상의 극단적인 값도 확인되었다. 이와 같은 결과를 통해 각 변수들의 중심 경향과 변동성을 확인할 수 있었으며, 데이터의 분포 특성을 파악함으로써 모델 학습 시 데이터의 특성을 반영한 전처리의 중요성을 시사하였다.
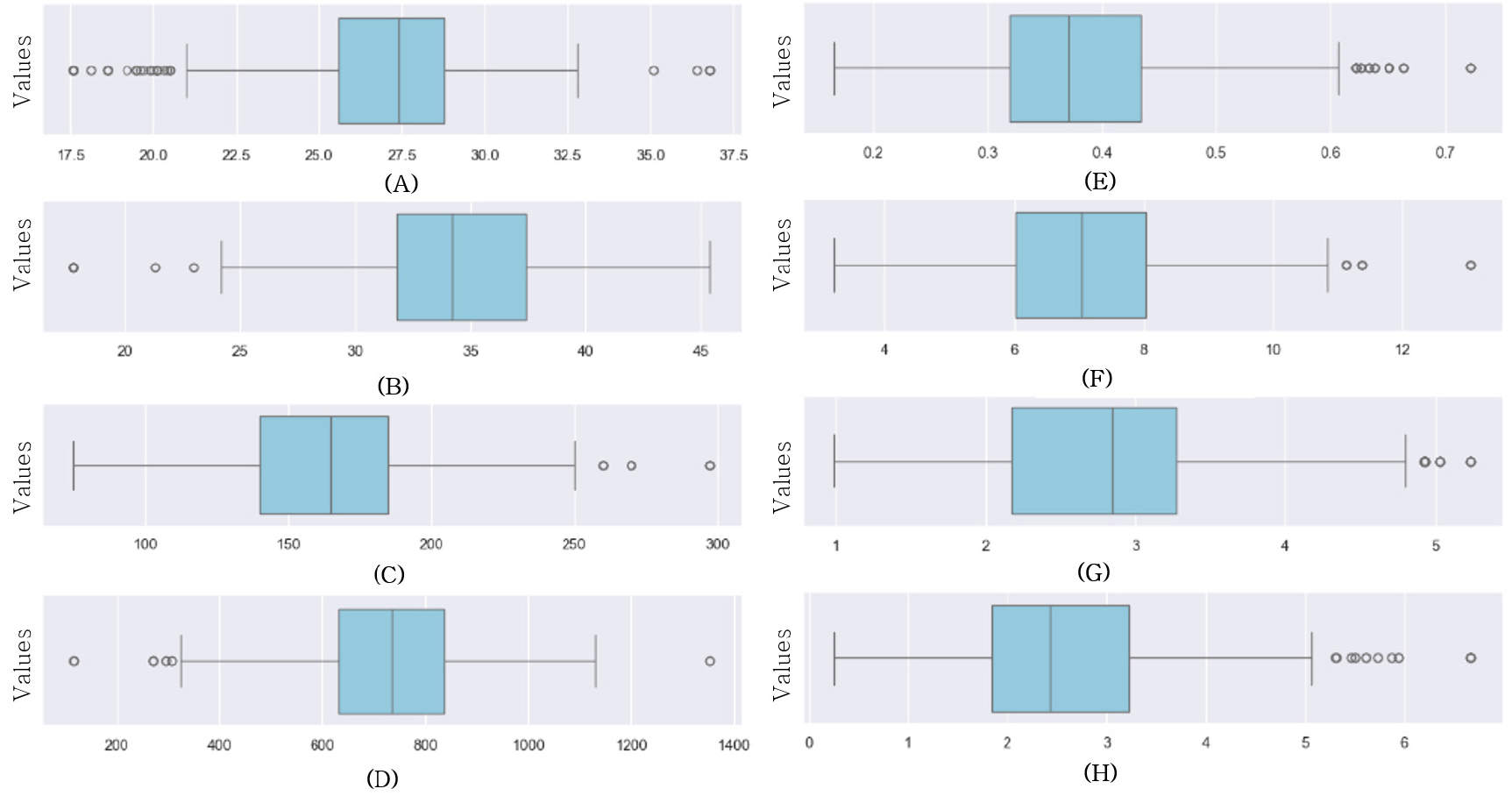
모델의 학습과정에서 이상치는 데이터 분포의 왜곡, 예측 성능의 저하 등 부정적인 영향을 미칠 수 있기에 전처리 과정에서 이상치의 영향을 최대한 줄이고자 하였다. 특히 농업데이터의 경우 실험 조건, 환경적 요인 그리고 생육 정보의 측정 오류로 인해 극단적인 값이 발생할 가능성이 높다고 판단하여 이상치 처리 방법을 선택하였다. 본 연구에서 초기 이상치 탐색 방법으로 IQR(Inter Quartile Range) 방식을 사용할 계획이었다. IQR방식은 전체 데이터를 오름차순으로 정렬하여 상위 25%와 하위 25% 데이터를 기준으로 중간 50%의 범위를 계산하고 이를 기준으로 1.5배 벗어난 값을 이상치로 간주하여 데이터의 중심을 잘 반영할 수 있는 방식이다. 그러나 본 연구에서 구축한 데이터 셋의 경우 연구데이터로 의도한 연구 환경 조건에서 발생한 극단적인 값이 실험 과정에서 의미를 가지는 경우가 있을 것이라 판단하여 단순히 제거하기보다 원저화(winsorization) 방식을 채택하였다. 원저화는 이상치를 제거하지 않고 상한값 또는 하한값으로 대체함으로써, 데이터의 분포를 유지하면서 극단값의 영향을 완화할 수 있는 방법이다. 구체적으로 각 변수에 대해 IQR을 기반으로 2.5배 벗어난 값을 통해 하한값과 상한값을 계산하고 이상치로 간주되는 값들을 해당 경계값으로 대체하는 방식인 원저화를 수행하였다.
원저화를 수행한 결과, 엽장, 엽폭에서 가장 많은 이상치가 발견되어 각 하한값, 상한값으로 대체되었다. 대체된 데이터의 중앙값 등 분포를 한 눈에 알 수 있도록 시각화 하였으며 이는 Fig. 3을 통해 확인할 수 있다.
해당 연구에서는 농업 환경의 다양성을 반영하기 위해 2.5배 IQR을 통해 이상치를 탐지하였으며 이를 통해 보다 광범위한 값들을 수용하면서도 명확히 극단적이라고 판단되는 값만 이상치로 간주하였다. 따라서 Fig. 3에서도 보이는 바와 같이 여전히 이상치로 탐지되지만 기준이 완화됨으로써 정상 데이터로 간주되는 값의 범위가 확장된 것을 확인할 수 있다. 생육 변수들의 경우 비교적 IQR의 범위가 좁은 것을 알 수 있는데 이는 데이터의 변동성이 적고 안정적인 패턴을 보이는 것을 의미한다.
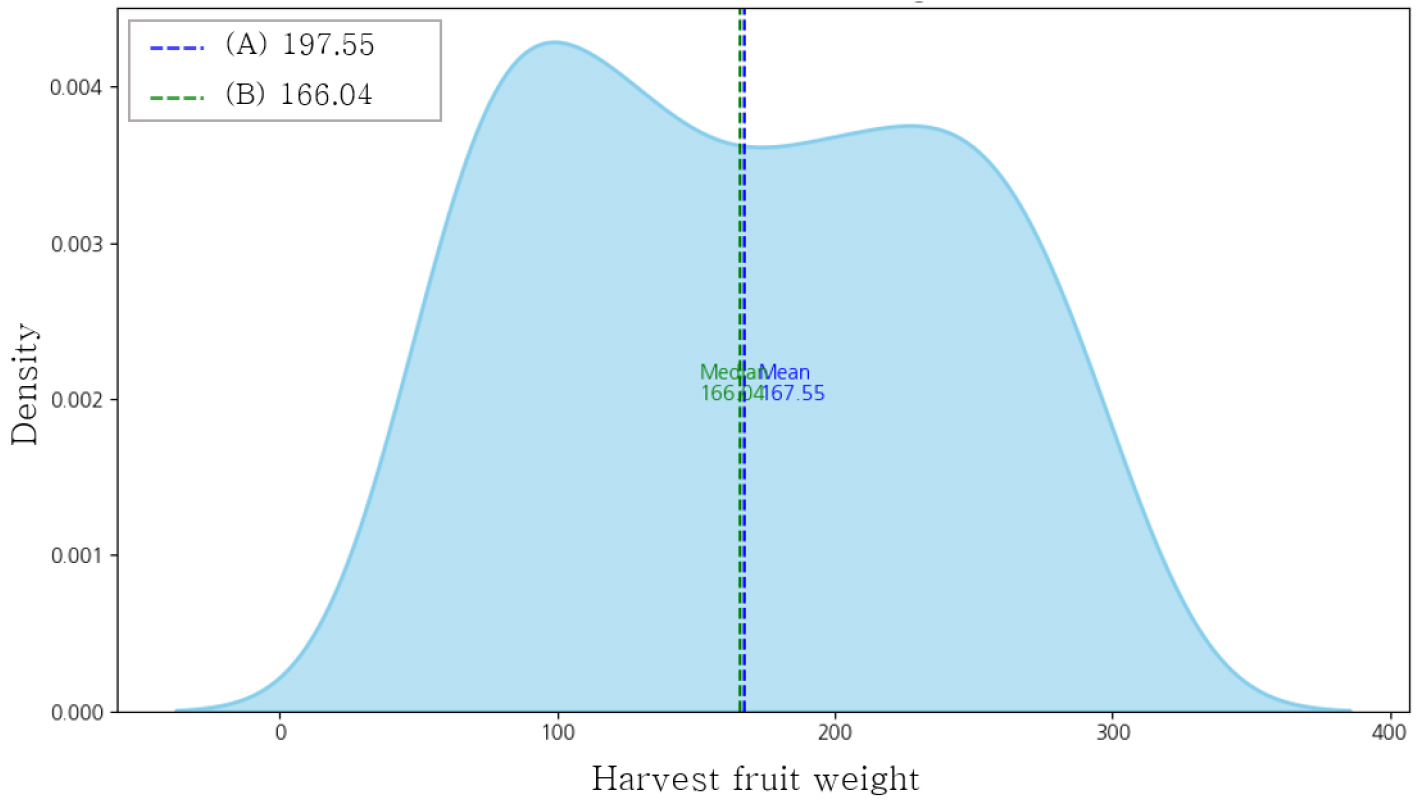
또한 Fig. 4와 같이 커널 밀도 추정(KDE, Kernel Density Estimate) 그래프를 통해 과중의 분포를 확인하였다. 커널 밀도 추정 그래프는 데이터의 밀도를 연속적인 곡선의 형태로 확인할 수 있어 부드럽고 직관적으로 파악할 수 있는 장점이 있다. 또한 데이터의 중심을 확인할 수 있는데 과중의 경우 중앙값이 166.04 g, 평균값이 167.55 g으로 데이터가 편향되지 않고 고르게 분포되어 있는 것을 확인할 수 있다. 왼쪽에서 오른쪽으로 부드럽게 증가하다가 100~300 g 사이에서 두개의 봉우리(이중 봉우리, bimodal 분포) 형태를 나타낸다. 이는 데이터의 수확 시기에 따라 과중이 달라졌을 가능성을 보인다. 그래프에는 평균값과 중앙값을 표시하였는데 두 값이 매우 가까운 것으로 보아 비교적 대칭적인 분포를 가지고 있음을 나타내며 큰 왜곡이 없음을 의미한다. 또한 과중의 밀도는 약 100~250 g 사이에 높게 집중되어 있으며 KED 플롯에서 꼬리부분(300 g 이상)이 매우 낮은 밀도를 가지는 것으로 보아 이상치가 데이터에 큰 영향을 미치지 않을 가능성이 있다.
분석 모델 설정
본 연구에서는 스마트농업에서 오이의 과중 예측 성능을 평가하기 위해 세 가지 딥러닝 모델인 GRU, 1D-CNN, Transformer의 성능을 비교하였다. 사용된 데이터는 스마트팜 R&D 빅데이터 플랫폼에서 수집되었으며, 연구개발(R&D) 과정에서 생성되는 데이터를 효율적으로 수집, 저장, 분석, 활용을 목적으로 구축된 플랫폼이다. 따라서 연구를 목적으로 하는 정형데이터와 이미지, 동영상 등 형식의 제한이 없는 비정형데이터가 적재되어 있으므로 공공데이터 활용을 목적으로 하는 본 연구에 적합하다고 판단되어 스마트농업의 연구개발 과정에서의 유용성을 평가하고자 하였다. 스마트팜 R&D 빅데이터 플랫폼은 정형데이터로 시설원예 분야에서 296개 DB 테이블, 축산 분야에서 179개 DB 테이블을 보유하고 있으며, 비정형 데이터는 총 39TB 규모로 적재되어 있다. 플랫폼은 데이터를 체계적으로 관리하기 위해 경영, 사양, 생산, 생육, 영농, 제어, 환경으로 구분된 7대 연구 분야로 분류하여 관리하고 있다. 이러한 분류는 스마트농업 관련 연구에 필요한 데이터를 보다 효율적으로 탐색하고 활용할 수 있도록 설계되었다. 데이터 분석 과정에서 변수 간 관계를 이해하기 위해 상관계수 시각화를 활용하였다. 다음으로, 상관계수 시각화를 통해 여러 변수 간 상관관계를 시각적으로 표현하여 데이터의 주요 패턴과 구조를 자세히 다룬다.
본 연구에서는 전체 데이터셋을 훈련: 검증: 평가(train: validation: test) 데이터셋으로 분할하여 딥러닝 모델의 예측 성능을 평가하였다. 시계열 데이터의 특성상 시간 의존성이 존재하여 데이터의 순서를 유지하는 것이 중요하다. 일반적으로 딥러닝에서는 예측 모델의 과적합(overfitting) 방지를 위해 교차검증(Cross-validation, CV)을 활용하지만, 시계열 자료는 시간 순서를 보존해야 하기 때문에 무작위로 데이터를 섞어 사용하는 일반적인 교차검증 방법을 적용하기 어렵다. 이를 극복하기 위해 10-fold cross-validation을 사용하였다. 이는 전체 자료를 일정한 크기의 K개의 블록으로 나눈 뒤 검증 블록을 제외한 나머지는 훈련 블록이 되는 KF CV (K-fold cross-validation) 방법이다(Berrar, 2019). Seo and Baek(2024)에 따르면 KF CV 방법은 모델의 예측 성능 측면에서 우수하다고 한다. 해당 방법을 도식화하면 Fig. 5와 같다.

앞서 말한 바와 같이 본 논문에서는 10-fold cross-validation을 통해 9개의 훈련데이터(train data)로 모델을 학습하고 1개의 검증데이터(validation data)를 이용하여 예측 성능 평가를 진행한다. 또한 과적합 방지를 위해 모델의 성능을 개선하는 드롭아웃(Dropout)을 적용하였다. 드롭아웃은 모델 훈련 중 신경망의 일부 뉴런을 무작위로 삭제하는 기법으로 모델이 특정 뉴런에 과도하게 의존하지 않도록 하는 역할을 한다. 드롭아웃은 전체 신경망 중 무작위로 선택된 뉴런을 비활성화함으로써, 과적합 위험을 줄이고 다양한 하위 네트워크가 결합된 모델이 되도록 한다(Srivastava et al., 2014). 이러한 기법을 통해 모델의 일반화 성능을 향상시킬 수 있다. 모델 학습에서 중요한 역할을 하는 하이퍼파라미터는 Batch Size, Epoch 수, Optimizer로 설정하였다. 각 모델(GRU, 1D-CNN, DNN)에 대해 동일한 하이퍼파라미터 값을 사용하여 공정한 성능 비교가 이루어지도록 하였다 (Table 3). 다만, 이러한 동일한 하이퍼파라미터 설정은 공정한 비교에는 유리하지만, 각 모델의 고유한 특성과 구조에 최적화된 성능을 충분히 끌어내는 데는 한계가 있다. 따라서 향후 연구에서는 모델별 하이퍼파라미터 튜닝을 통해 예측 성능을 더욱 향상시킬 수 있을 것이다.
Table 3.
Key hyperparameters consistently applied in model training.
| Batch size | Epoch | Optimizer |
| 64 | 500 | Adam |
이러한 설정은 모델이 과적합을 방지하고 안정적인 학습이 가능하도록 도와주며, 최적의 예측 성능을 도출하는데 중요한 역할을 한다. 특히 Optimizer로 설정한 Adam(Adaptive Moment Estimation)은 학습률을 자동으로 조정해주는 특성을 가지고 있어 딥러닝 모델의 훈련속도와 성능을 향상시키는데 유리하다(Kingma and Ba, 2014). 이와 같이 모델의 과적합 위험을 줄이고 오이의 과중 예측을 위해 세가지 딥러닝 모델인 GRU, 1D-CNN, DNN를 적용하였다. 각 모델은 시계열 데이터의 특성을 반영하여 예측 정확도를 높이기 위해 설계되었으며 그 구조와 특징은 아래에서 각각 상세히 설명한다.
GRU는 두 개의 게이트로, 하나는 이전 상태의 정보를 얼마나 가져와야 할지를 결정하는 업데이트 게이트(update gate)로 다시 말해 장기 기억을 담당하는 게이트이다. 이 게이트를 통해 모델이 모든 과거 데이터를 복제하도록 결정할 수 있어 기울기 소실 가능성을 제거할 수 있어 매우 유용하다. 업데이트 게이트는 식 (4)와 같이 정의되며, 는 업데이트 게이트, σ는 시그모이드 함수, 는 현재 입력(input), 와 는 자체 가중치, 은 이전 은닉 레이어를 의미한다(Wang et al., 2018).
다른 하나는 이전 상태를 얼마나 잊어야 하는지를 결정하는 리셋 게이트(reset gate)로 다시 말해 단기 기억을 담당한다. 업데이트 게이트와 공식은 동일하며 차이점은 가중치와 게이트 활용에 있다. 이와 같이 GRU는 RNN(Recurrent Neural Network)의 기울기 소실(vanishing gradient) 문제를 해결하는 LSTM(Long Short-Term Memory)의 간소화 모델로 알려져 있으며, 앞서 언급한 두 가지의 게이트를 사용하여 효율적인 계산으로 LSTM에 비해 빠른 학습 시간을 가지며 계산량이 적은 특징을 가지고 있다. 따라서 데이터 양이 많지 않은 스마트농업 분석에 적합할 것이라 예상되어 활용하였다.
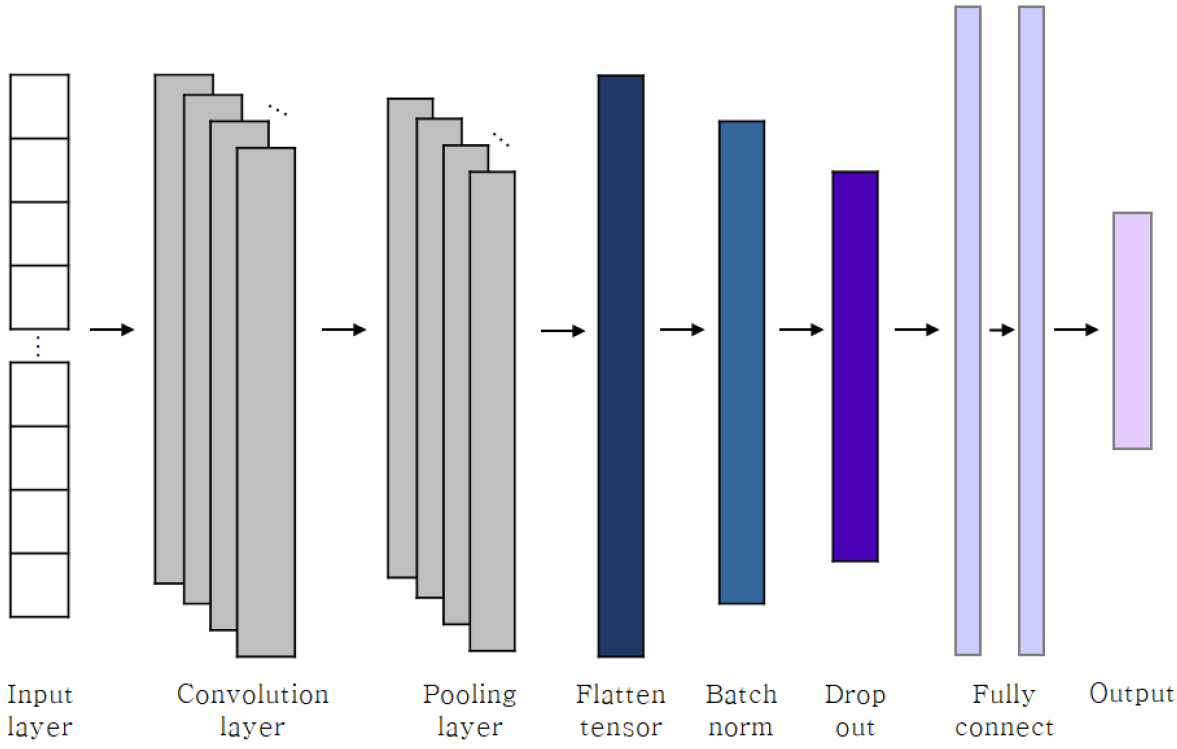
1D-CNN은 1차원 합성곱 신경망 구조로, 1차원 데이터에 대한 합성곱 연산을 수행하도록 설계된 신경망 구조 알고리즘이다. 합성곱 연산의 상호관계를 분석하는 기능을 가지면서 1차원 데이터를 분석하는데 용이하여 주로 시계열 데이터와 같이 한방향으로 연속된 데이터 분석에 탁월한 성능을 보이는 알고리즘이다(Kiranyaz et al., 2021). 1D-CNN의 기본 구조는 Fig. 6과 같다. 합성곱 필터를 사용하여 입력데이터 위를 스캔 및 이동하면서 주변 값을 확인하고 패턴을 인식하는 합성곱 레이어(convolutional layer)와 공간적 차원을 줄이고 계산량을 감소시키는 풀링 레이어(pooling layer) 마지막으로 풀링층의 출력을 이용하여 최종 예측을 수행하는 완전 연결 레이어(Fully connected layer)로 구성되어 있다. 이러한 특성과 같이 다른 순차적 모델에 비해 구현이 상대적으로 간단하기 때문에 과적합 문제를 덜 겪을 것이라 판단하여 선정하였다.
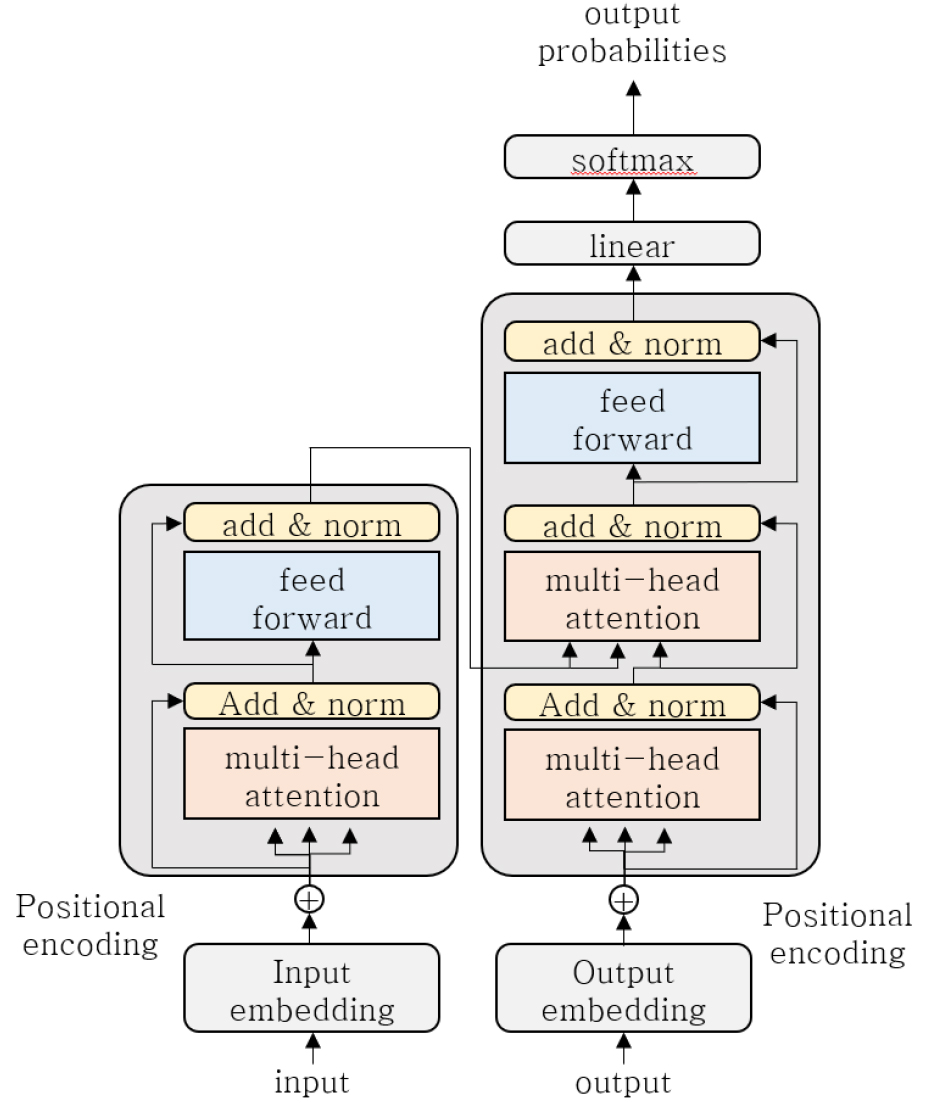
Transformer 모델은 (Vaswani et al., 2017)에 의해 제안된 Self-Attention 메커니즘을 기반으로 한 딥러닝 모델이다. Transformer 모델은 RNN(순환 신경망)모델이나 CNN(합성곱 신경망)과 달리 입력 시퀀스의 관계를 Self-Attention 메커니즘을 통해 직접 학습한다. Self-Attention 메커니즘은 시퀀스 내의 각 요소들이 서로 어떻게 연관되는지 상관관계를 계산한다. 이 구조는 시퀀스 데이터를 병렬 처리에 효율성을 극대화하며, 멀티헤드 어텐션(Multi-Head Attention)은 여러 개의 어텐션 헤드를 사용하여 각기 다른 정보의 관점을 동시에 학습하여 모델의 성능을 더욱 향상시킨다. 본 연구에서는 시계열 데이터로 입력 시퀀스를 처리하고, 시퀀스 길이를 줄여주는 역할을 하는 GlobalAveragePooling1D 레이어를 사용하였다. 이를 통해 모델의 차원을 축소하고 과적합을 방지하여 모델의 학습 및 예측을 보다 효율적으로 수행할 수 있다(Fig. 7).
Transformer모델은 Self-Attention 메커니즘을 사용하여 시계열 데이터에서 시간에 따른 의존성을 잘 학습할 수 있을 뿐만 아니라 Multi-Head Attention을 통해 시계열 데이터 내에 여러 시간대 간의 관계를 동시에 학습할 수 있게 해주어 다양한 입력 변수들 간의 상호작용도 효과적으로 반영할 수 있을 것이라 판단했다. 또한 본 연구에서는 두 작기의 환경 변수와 생육 변수를 결합하였기 때문에 이 과정에서 다양한 변수들 간의 복잡한 관계를 처리하는데 적합할 것이라 예상한다.
모델 성능 지표
모델의 성능을 평가하기 위해 평균 절대 오차(Mean Absolute Error, MAE)를 사용하였다. MAE는 식 (5)와 같이 예측값과 실제값 사이의 차이를 절대값으로 평균 낸 지표로 절대 오차의 평균을 나타낸다. 각 오차의 크기를 무시하지 않고 평균하기 때문에 이상치의 영향이 크게 받을 수 있다. MAE는 값이 낮을수록 모델의 예측 정확도가 높음을 의미한다(Shi et al., 2017).
반면 R2은 모델이 데이터를 얼마나 잘 설명하는지를 나타내는 지표로 실제 값의 변동에 대한 모델의 설명 비율을 나타낸다. R2은 0에서 1사이의 값을 가지며, 1에 가까울수록 모델의 적합성을 평가할 수 있다. 독립변수인 x와 종속변수 y로 이루어진 n개의 회귀분석 샘플이 존재할 때 아래 식 (6), (7), (8)에 의해서 값이 구해지며 여기서 은 i번째 종속 변수, 은 의 평균이며, 는 회귀분석 오차이다.
MAE와 R2은 서로 보완적인 역할을 하며 MAE는 직관적인 오차 크기를 제공하고, R2는 모델의 설명력을 측정하는데 유용하다. 따라서 본 연구에서는 가장 작은 MAE와 가장 큰 R2값을 가진 모델을 선정하여 성능을 비교하였다.
Results and Discussion
본 연구는 GRU, 1D-CNN, Transformer 세 가지 딥러닝 모델을 대상으로, 스마트농업 공공 빅데이터를 활용한 오이 과중 예측 성능을 비교·분석하여 모델의 적용 가능성과 데이터셋의 활용성을 검증하고자 하였다.
데이터 분석 결과 및 시각화
Fig. 8과 같이 상관계수 시각화는 변수 간 상관관계와 데이터 분포를 직관적으로 보여준다. 엽장과 엽폭과 같은 생육 변수들 간에는 매우 높은 상관성이 나타났으며, 생육 변수와 환경변수인 내부 온도 간에도 강한 양의 상관관계가 관찰되었다. 이는 적절한 온도 관리가 작물 생육에 긍정적인 영향을 미친다는 것을 시사한다. 반면, 내부 온도와 내부 상대습도는 음의 상관관계를 보여, 온도와 습도 간의 복합적인 상호작용이 생육에 영향을 줄 수 있음을 나타낸다. 또한, 주차(시간 흐름)와 생육 변수 간의 약한 양의 상관관계를 통해 생육의 시간적 패턴을 추론할 수 있었으며, 일사량과 내부 온도의 자연스러운 양의 상관성도 확인되었다. 전체적으로 Pair plot을 통해 생육변수간 서로 밀접한 관계와 환경 변수와도 긴밀하게 연결되어 있음을 알 수 있었다.

모델 성능 검증
모델의 예측 성능을 종합적으로 평가하고 비교하기 위해 평균 절대 오차(Mean Absolute Error, MAE)와 결정 계수(R2)라는 두 가지 주요 평가 지표를 사용하였다. Table 4의 결과에 따르면 세 가지 딥러닝 모델 모두 우수한 성능을 보였으며, 이는 스마트 농업 데이터 분석에 AI 모델을 적용할 수 있는 가능성을 보여준다.
Table 4.
Average prediction results by performance metrics for the model proposed in this study.
| Models | Evaluation Metrics | Value |
| GRU | MAE | 3.5735 |
| R2 | 0.9728 | |
| 1D-CNN | MAE | 3.8413 |
| R2 | 0.9733 | |
| Transformer | MAE | 0.1584 |
| R2 | 0.9999 |
Transformer 모델은 MAE 0.1584, R2 0.9999로 가장 높은 예측 정확도를 기록하였다. 이는 Self-Attention 메커니즘을 기반으로 한 시계열 종속성 학습 능력이 복잡한 생육·환경 변수 간 관계를 효과적으로 반영했기 때문으로 해석된다. 특히 높은 무게 구간에서 예측값이 실제값과 거의 일치하며 탁월한 성능을 보였다. 하지만 낮은 무게 영역에서는 소폭의 오차가 발생했으며, 이는 모델의 민감도 및 견고성 측면에서 추가적인 최적화가 필요함을 시사한다.
GRU 모델은 MAE 3.5735, R2 0.9728로 높은 성능을 보였다. GRU는 시계열 데이터의 장기 의존성을 효과적으로 포착하는 데 강점을 가지며, 상대적으로 단순한 구조 덕분에 빠른 학습과 연산 효율성을 확보할 수 있었다. 특히 낮은 무게 구간에서 예측 정확도가 높아, 실시간 환경에서 안정적인 예측을 요구하는 스마트농업에 적합한 모델로 볼 수 있다.
1D-CNN 모델은 MAE 3.8413, R2 0.9733을 기록하며 안정적인 예측 성능을 나타냈다. 국소적 특징 추출에 특화된 1D-CNN의 구조는 시계열 데이터에서 의미 있는 패턴을 효과적으로 포착하여 일정 수준 이상의 예측 성능을 확보하였다. 모델 구현이 상대적으로 간단하며, 연산 자원이 제한된 환경에서도 실용적인 대안이 될 수 있다.
Fig. 9는 각 모델별 예측 결과를 실제 값과 비교하는 산점도를 나타낸다. x축은 실제 오이의 과중, y축은 모델이 예측한 오이의 과중이며, 빨간색 점선은 이상적인 예측을 나타내며 모든 점이 이 선에 가까울수록 예측이 정확도가 높음을 의미한다. 이를 통해 각 모델의 성능을 직관적으로 비교할 수 있으며, 예측값이 실제값과 얼마나 일치하는지 시각적으로 확인할 수 있다.
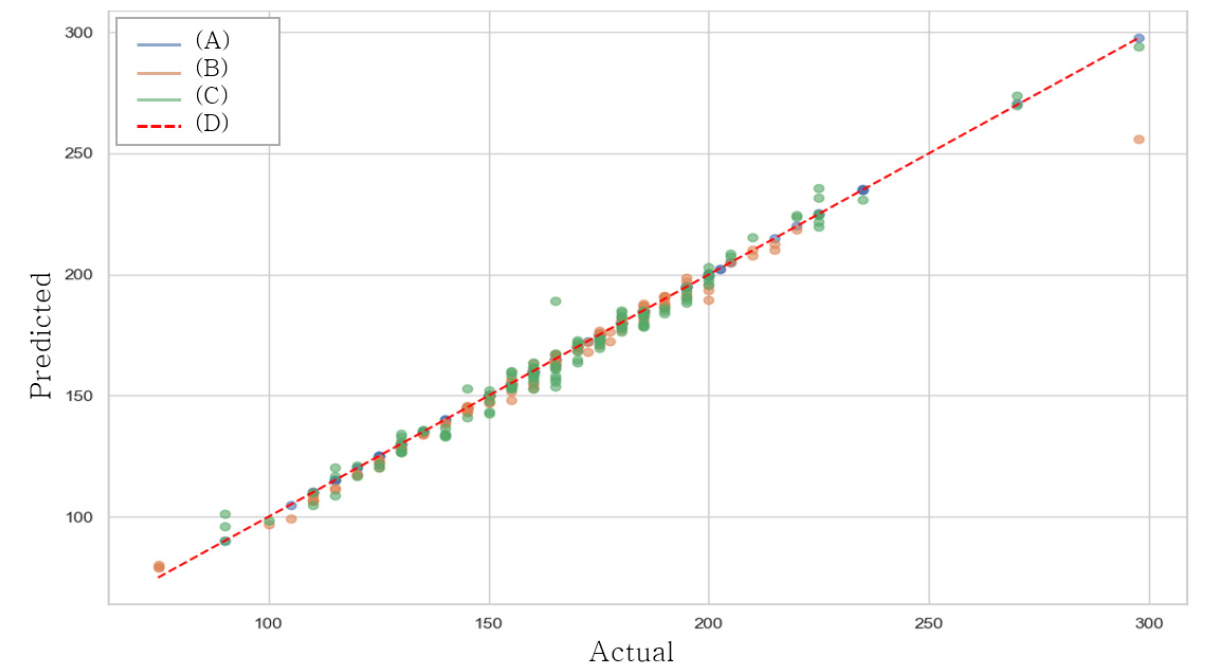
GRU 모델은 전반적으로 낮은 무게 구간에서 점선에 매우 근접한 분포를 보이며, 해당 구간에서 안정적인 예측 성능을 보였다. 1D-CNN 모델은 전체 구간에 걸쳐 가장 균일한 오차 분포를 보였으며, 다양한 과중 데이터를 고르게 처리하는 경향을 나타냈다. 다만, 극단적인 값(예: 100g 이하 또는 250g 이상)에서 소수의 오차가 발생하였다. 마지막으로 Transformer 모델은 높은 무게 구간에서 점선에 밀접하게 분포하여 이 구간의 예측에서 가장 뛰어난 성능을 나타냈다. 그러나 낮은 무게 영역에서는 다른 모델에 비해 다소 큰 오차가 관찰되었다.
Transformer는 높은 무게 예측에, GRU는 낮은 무게 구간에, 1D-CNN은 전 범위에 걸친 예측 안정성에 각각 강점을 보였다. 결과적으로 세 모델은 예측 구간에 따라 상호 보완적인 특성을 가지며, 특정 목적에 맞는 모델 선택이 중요함을 시사한다.
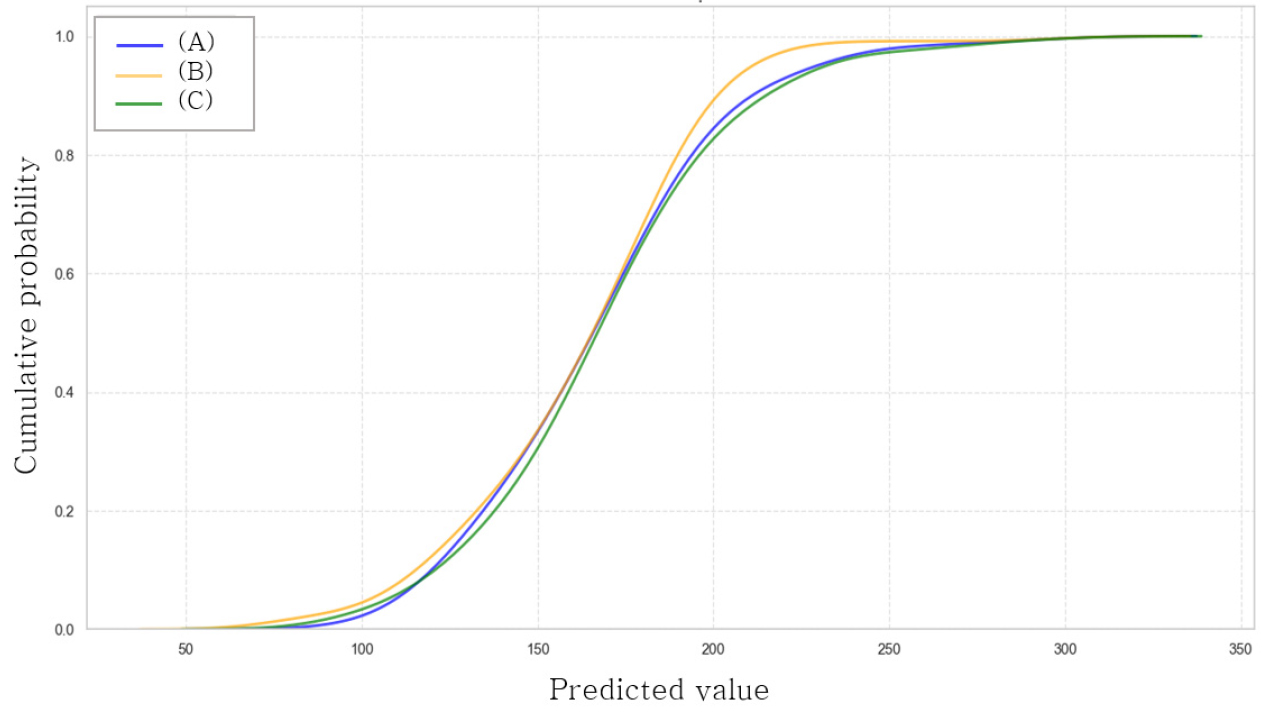
Fig. 10은 누적분포함수(CDF, Cumulative Distribution Function)를 활용하여 모델별 예측값의 분포 특성을 시각화한 결과이다. 누적분포함수는 특정 값 이하의 예측값이 전체 데이터에서 차지하는 비율을 의미하며, x축은 예측된 과중, y축은 누적 비율을 나타낸다. GRU 모델은 낮은 무게 영역에서 가장 빠르게 누적 확률이 증가하는 패턴을 보였으며, 예측값이 100~250 g 구간에 집중되는 경향을 보였다. 이는 GRU 모델이 해당 무게 구간에서의 예측에 적합함을 시사한다. 1D-CNN 모델은 전체 구간에 걸쳐 고르게 분포된 누적 곡선을 보이며, 특정 구간에 편향되지 않은 균형 잡힌 예측 성능을 나타냈다. 이는 GRU와 Transformer의 특성을 절충한 형태로 볼 수 있다. Transformer 모델은 250 g 이상의 높은 무게 구간에서 누적 확률이 급격히 상승하며 해당 영역에서 탁월한 예측 성능을 보여주었다. 다만, 낮은 무게 구간에서는 누적 확률의 증가가 완만하게 나타나 상대적으로 성능이 낮았다.
결론적으로 본 연구에서는 Transformer 모델을 포함한 다양한 딥러닝 모델들이 모두 좋은 성능을 보였음을 확인하였다. Transformer 모델은 특히 시계열 데이터와 높은 무게 예측에서 강점을 보였으며, GRU모델은 낮은 무게 예측에서 안정적인 성능을, 1D-CNN모델은 고른 분포와 예측 안정성을 보여주었다. 이러한 결과를 통해, 스마트 농업 분야에서는 다양한 모델들이 서로 보완적인 역할을 할 수 있으며, 각 모델의 특성에 맞게 활용할 수 있다는 가능성을 보여주었다. 본 연구 결과는 스마트농업에서 실시간 온실 관리, 작물 수확량 예측, 생육 환경 제어와 같은 다양한 응용 분야에 활용될 수 있음을 보여준다. 특히 시계열 데이터를 효과적으로 다루는 GRU 모델과 대규모 데이터 분석에 강점을 가진 Transformer 모델의 특성을 적절히 조합하면, 스마트농업의 효율성과 정확도를 더욱 향상시킬 수 있을 것이다. 이러한 활용 가능성은 데이터 기반 스마트농업의 효율성과 정확도를 향상시키는 데 기여할 수 있다. 이렇듯 본 연구에서의 모델 학습 결과는 스마트 농업 분야에서 활용될 수 있는 중요한 기초 자료를 제공하며, 향후 경영, 제어 등 다양한 데이터를 활용하여 예측 정확도를 더욱 향상시킬 수 있을 것으로 기대된다.
본 연구에서는 모델 성능 측면에서 우수한 결과를 도출하였으나, 단일 스마트 농장에서 수집된 데이터셋을 사용했다는 한계가 존재한다. 이러한 제한점은 연구 결과의 일반화 가능성(generalizability)을 저해할 수 있으며, 다양한 환경 조건과 재배 방식에 대한 적용성을 낮출 수 있다. 따라서 기후 및 농업 관리 방식이 다른 여러 농장에서 수집된 데이터를 포함한다면, 모델의 견고성(robustness)과 실용성이 더욱 향상될 것이다.
본 연구에서는 주요 생육 및 환경 요인을 고려하였으나, 토양 조성(soil composition), 양분 가용성(nutrient availability), 해충 발생률(pest incidence)과 같은 추가적인 변수는 포함되지 않았다. 이러한 요인들을 통합할 경우, 예측 정확도가 더욱 향상될 뿐만 아니라, 오이 생육의 역학(dynamics)에 대한 보다 포괄적인 이해를 제공할 수 있을 것이다.
또한, 트랜스포머(Transformer) 모델이 가장 우수한 예측 성능을 보였으나, 고급 하이퍼파라미터 튜닝(advanced hyperparameter tuning) 및 앙상블 학습(ensemble learning) 기법을 활용한 추가적인 최적화를 통해 모델의 정확도와 안정성을 더욱 향상시킬 수 있을 것이다. 본 연구에서는 모델 성능 평가를 위해 10-폴드 교차 검증(10-fold cross-validation)을 사용하였으나, 시계열 데이터에 보다 적합한 검증 기법인 순차적 검증(walk-forward validation)과 같은 대체 검증 방법을 활용할 경우, 모델의 일반화 성능을 보다 신뢰성 있게 평가할 수 있을 것이다.
Conclusions
본 논문에서는 국내 스마트농업 빅데이터 플랫폼에서 수집된 생육 및 환경 데이터를 기반으로, 딥러닝 기반 작물 생육 예측 모델을 개발하고 평가하였다. GRU, 1D-CNN, Transformer 세 가지 딥러닝 모델을 활용하여 오이 과중 예측을 수행하였으며, 모델 성능 비교를 통해 각 모델의 특징과 적용 가능성을 분석하였다.
데이터 품질 향상과 예측 성능 극대화를 위해 다양한 전처리 전략을 적용하였다. 첫째, 본 연구에 활용된 데이터는 정제도가 높아, 결측치 보간을 위한 별도의 처리는 수행하지 않았다. 둘째, 생육과 환경 변수 간의 상호작용을 반영한 복합 지표를 생성하여 모델 입력 변수의 표현력을 강화하였다. 셋째, 측정 오류나 극단값에 의한 왜곡을 최소화하기 위해 원저화 기법을 통해 이상치를 처리하였다. 특히, 생육 데이터는 현장에서 수작업으로 측정되므로 오차 가능성이 존재하며, 연구 목적에 따라 일부 극단값은 의도된 정보일 수 있어 단순 제거보다는 보정이 필요하였다.
예측 모델 학습에는 10-fold 교차 검증을 적용하여 일반화 성능을 확보하였다. 성능 평가 결과, Transformer 모델이 MSE와 R2 지표 모두에서 가장 뛰어난 예측 정확도를 기록하였으며, 특히 고중량 구간에서의 예측 능력이 탁월함을 확인하였다. GRU와 1D-CNN 모델 역시 비교적 안정적인 성능을 보였으며, 데이터 구성이나 변수 확장에 따라 성능 향상 가능성이 존재함을 시사하였다.
이러한 결과는 각 모델의 구조적 특성과 데이터 구간별 성능 차이를 이해하고, 이를 바탕으로 스마트농업의 다양한 시나리오에 맞는 모델 선택과 적용 전략을 수립할 수 있음을 의미한다. 또한, 본 연구는 공공 농업 빅데이터의 실질적인 활용 가능성을 입증하였다는 점에서 의미가 크다.
향후 연구에서는 다음과 같은 보완이 필요하다. 첫째, 모델의 일반화 성능을 높이기 위해 다양한 지리적 지역과 환경 조건에서 수집된 데이터셋을 포함하는 것이 필요하다. 둘째, 토양 품질, 양분 수준, 관개 변수 등 추가적인 농업 변수(agronomic variables)를 포함하면 예측 정밀도를 더욱 높일 수 있다. 셋째, 본 연구에서 제안한 모델을 실시간 스마트 농업 시스템(real-time smart farming systems)에 실제로 적용하고 성능을 검증하는 후속 연구가 필요하다. 특히, 지속적으로 수집되는 데이터를 활용할 수 있는 연속 학습(continuous learning) 기반의 모델 개발은 실환경 적용성을 크게 향상시킬 수 있을 것이다. 본 연구는 스마트농업 데이터 기반 예측 모델 개발의 실증 사례로서, 향후 다양한 작물 및 환경 조건에의 확장 가능성을 제시하였다.
